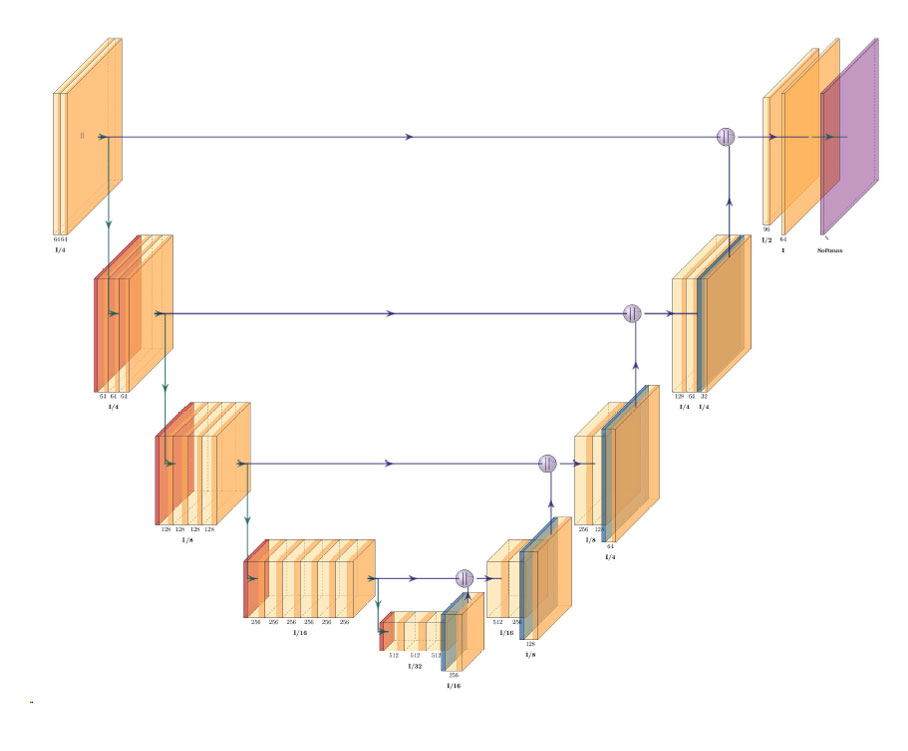
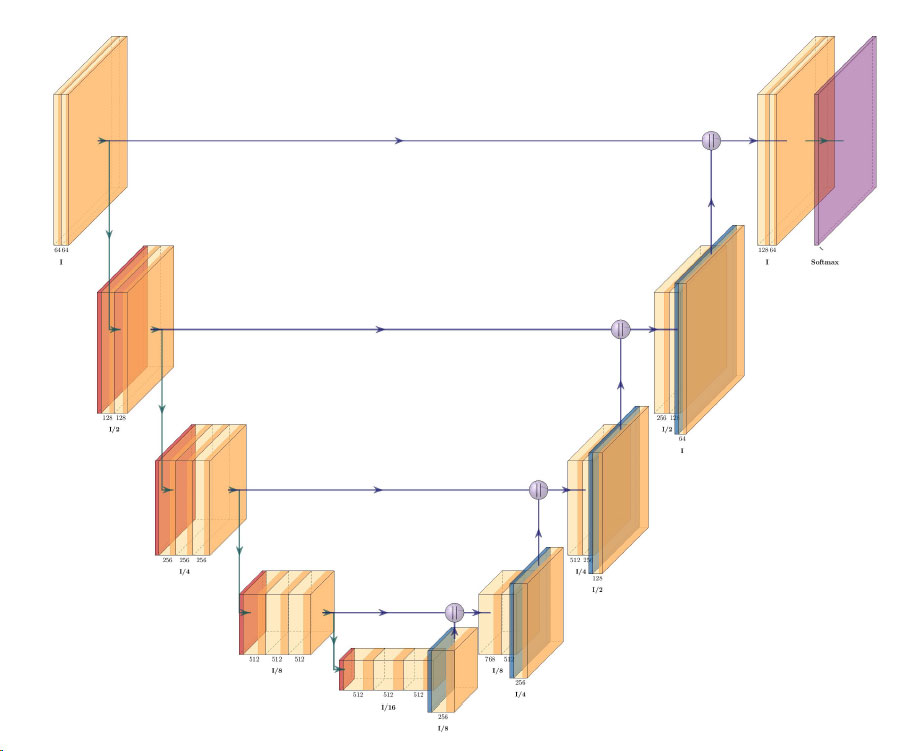
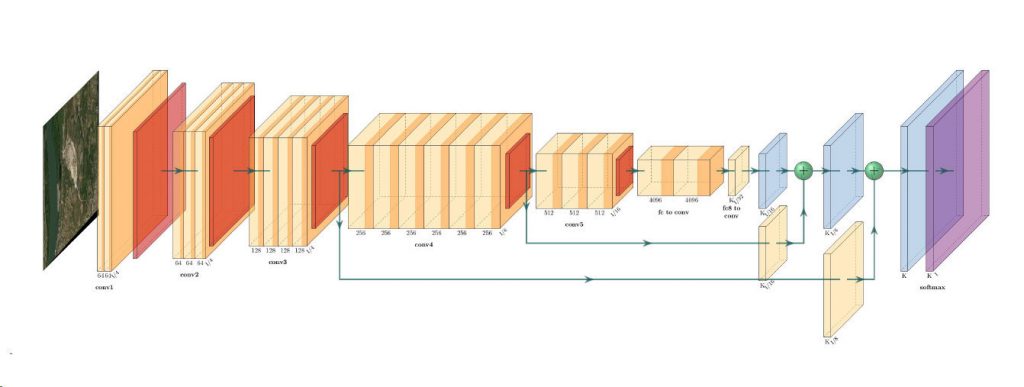
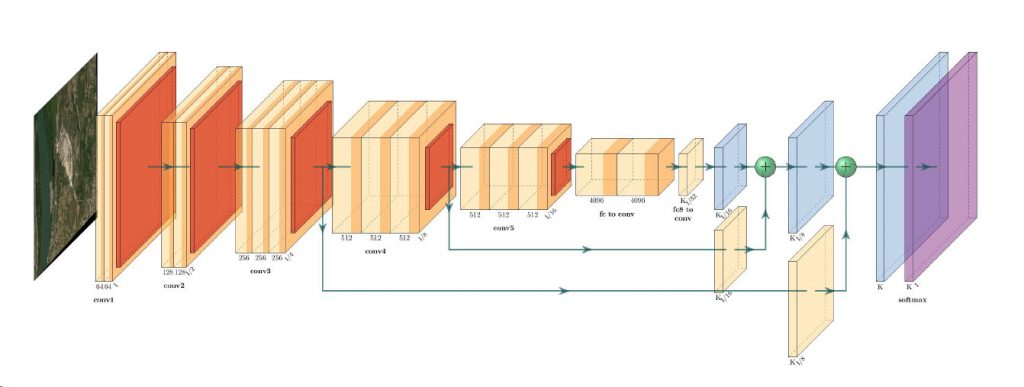
![{
bandList =
[
4;
3;
2;
]
}](https://www.euspaceimaging.com/wp-content/uploads/elementor/thumbs/10AUG09_WV_EUSI-Italy-Amatrice_before_Earthquake_800px-qtba7w8amtjrf28lj4ettjssnqwbv08vo7t52ed5jy.jpg "{ bandList = [ 4; 3; 2; ]}")


EUSI Upgrades German Ground Segment to Enable Europe’s Fastest Request-to-Receive Satellite Intelligence via Secure Web and API Platform for Defence and Emergency Agencies
European Space Imaging (EUSI) announced a major upgrade of its satellite ground segment and cloud infrastructure, further accelerating its industry-leading satellite tasking and intelligence delivery capabilities through the secure ATOM™ web and API platform. The platform, in combination with EUSI’s Rapid Satellite Intelligence (RSINT) program, enables satellite tasking up to 30 minutes before image acquisition and delivery of imagery within 15 minutes of collection.

Maritime Domain Awareness in European Arctic Regions With VHR Satellite Intelligence
With the Arctic warming nearly four times faster than the average, the ice in the High North is melting and the sea is becoming increasingly navigable. In 2025 alone, 1812 vessels entered the Arctic Polar Code area, which is a 40% increase since 2013 when data collection began. While this rise in traffic presents potential commercial opportunities, more vessels also mean more risks to people and resources.

Seeing More in a Single Day: The Value of Intraday Satellite Collections
Imagine a convoy moves between 08:00 and 11:00. Or morning clouds clear by 14:00, revealing new activity. Or a structure appears at 09:30 that wasn’t visible at 07:00. If you’re working with once-daily satellite passes, you miss all of this. With intraday collections, you see it happen.

GEOSeries: Maintaining Temporal Control of Developing Situations With Rapid Satellite Tasking and Intraday Imaging
In the fast-moving operational environments of security monitoring and emergency response, the value of satellite data is defined by when it arrives, not just its resolution or accuracy. This webinar explores how Dynamic Tasking enables users to access actionable data fast and operate within mission decision windows.