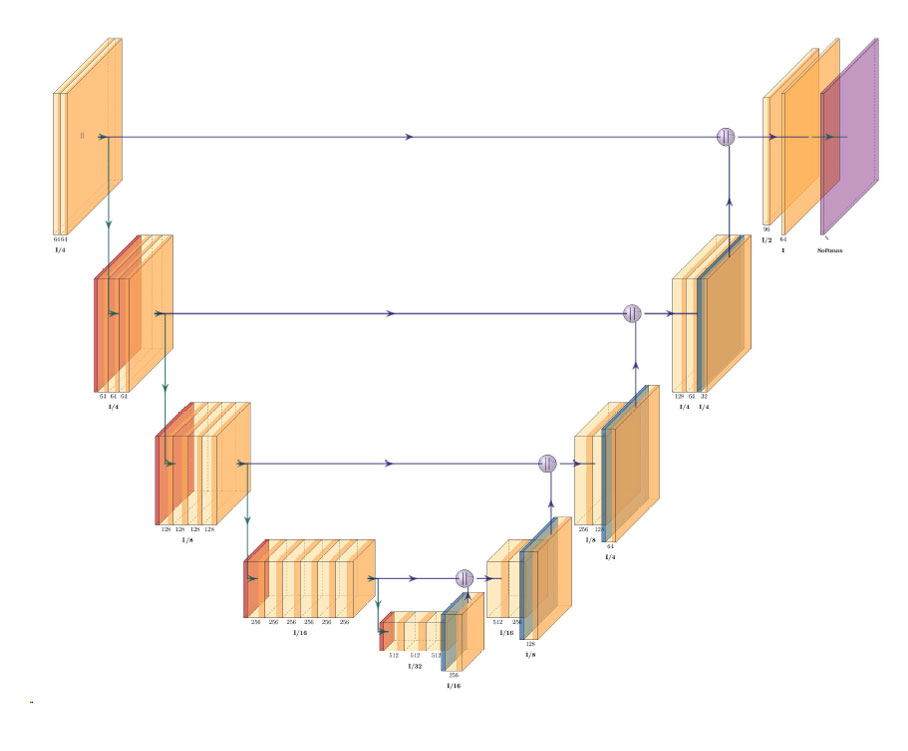
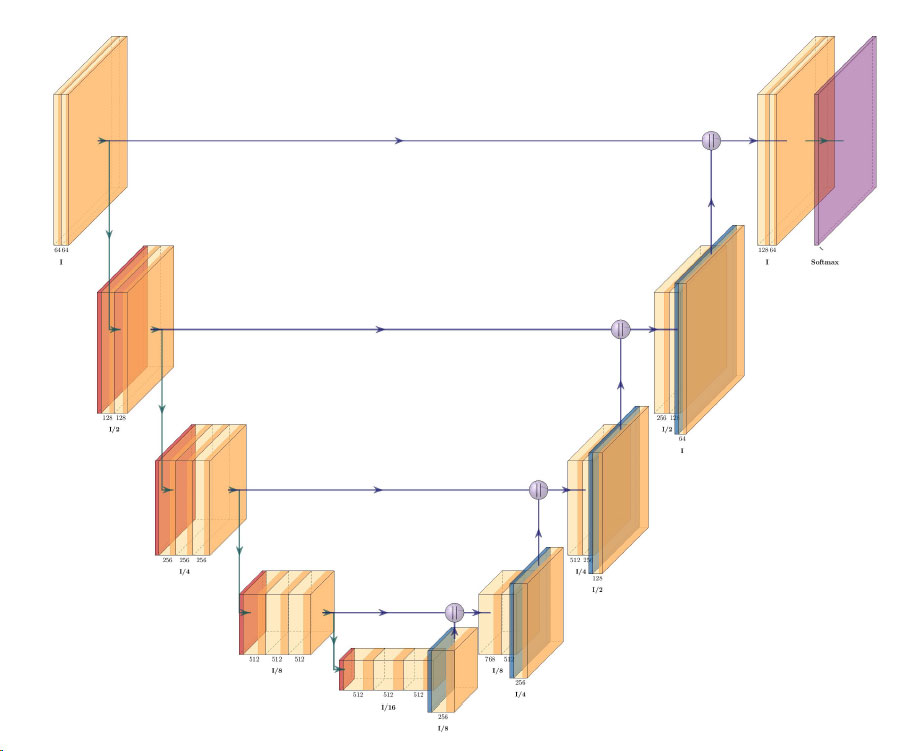
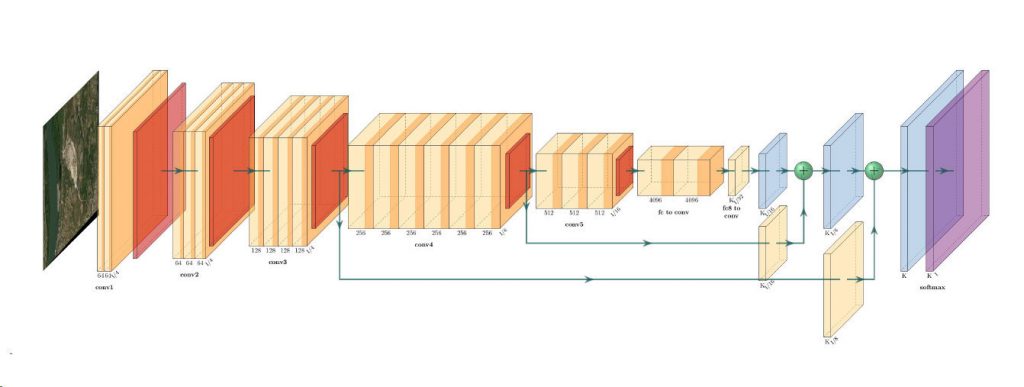
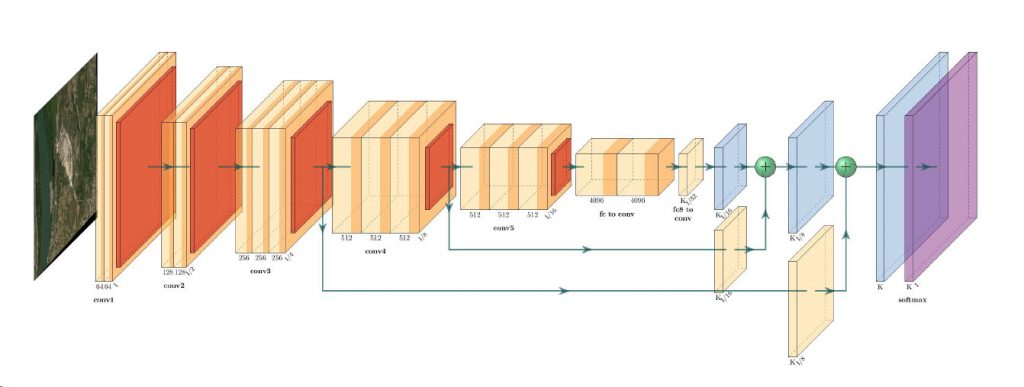
The Remote Sensing Laboratory at the National Technical University of Athens, Greece, successfully correlated vegetation indices derived from pansharpened multispectral WorldView-2 data with ground-based…
Greece has the longest tourist coastline in Europe, and its beaches are the property of all citizens. Each summer, coastal municipalities grant permits for…
THE 123 OF AEC: Renewing the Architecture, Engineering and Construction Industry with Satellite Imagery | A reoccurring sustainable issue faced by the Architecture, Engineering…
On Friday 6 November, Satellogic, the first company to develop a scalable Earth observation platform with the ability to remap the entire planet at…
Today the DigitalGlobe WorldView-3 satellite was launched from Vandenberg Air Force Base in California. The satellite was sent up on a United Launch Allliance…
European Space Imaging is excited to announce we are now accepting orders for 30 cm WorldView-3 satellite imagery products. According to DigitalGlobe users can…
IKONOS outlived many of its younger siblings but today it is time to say goodbye. After 15-plus years of successful service, DigitalGlobe made the…
Dr. Angelika Niebler visits European Space Imaging. Europe’s leading provider of high-resolution satellite imagery received a visit last Tuesday from Dr. Angelika Niebler, Member…
European Space Imaging completed the 2015 Controls with Remote Sensing (CwRS) program for the European Commission (EC) with 100 % success rate. The Munich-based…