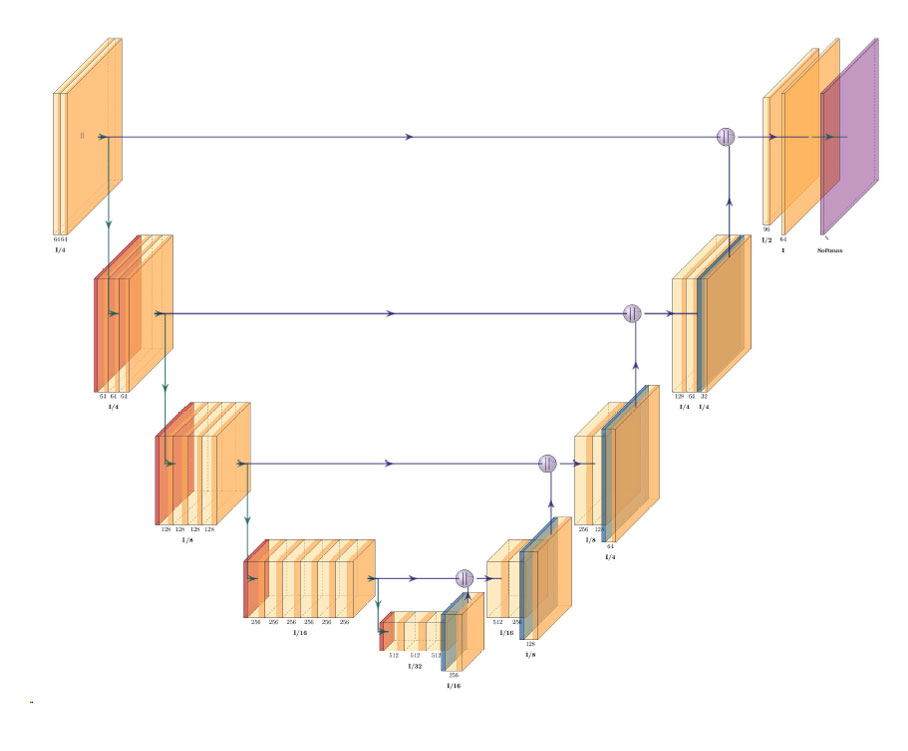
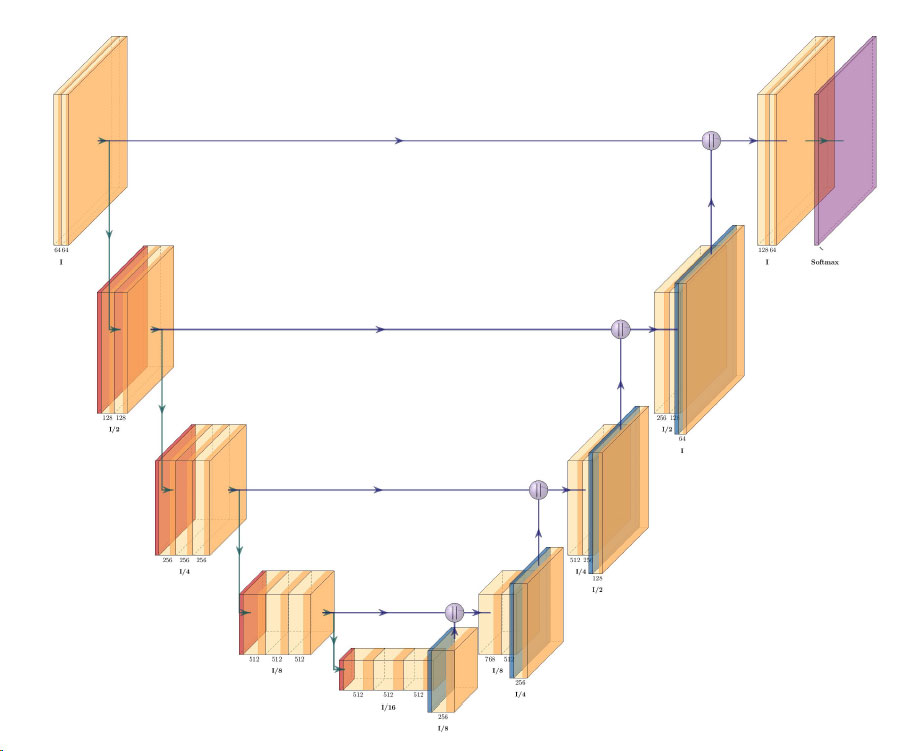
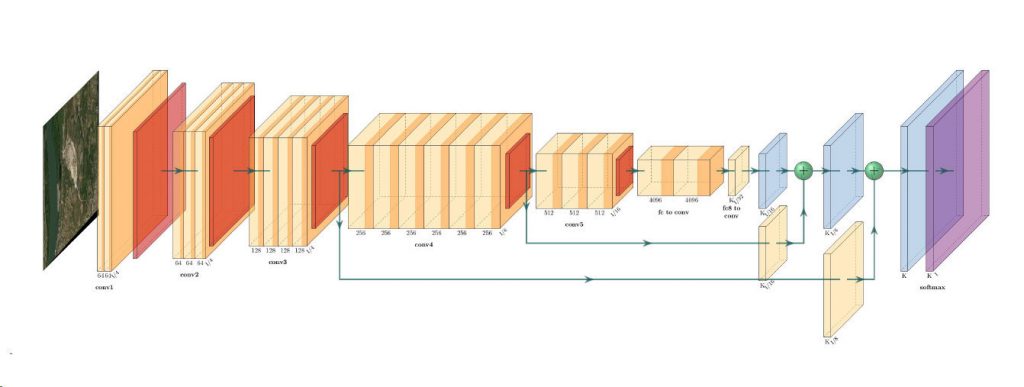
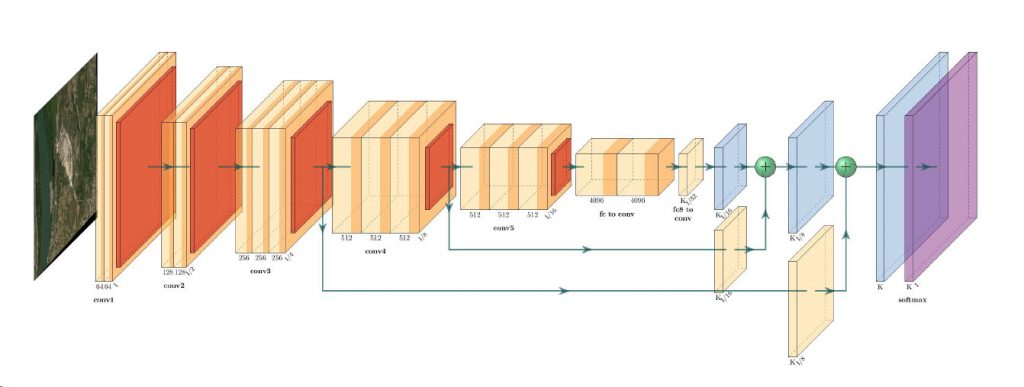
wORLDVIEW-3 WorldView-3 was launched on August 13 2014, and truly set a new standard for commercial satellites in-orbit. With 29 spectral sensors on-board, the…
SEEING THROUGH THE TREES: Monitoring Agriculture and Forestry Using Satellite Imagery | Agriculture provides us with food, fuel, fibers and raw materials that are…
While Russia remains in conflict with Ukraine, and the future of the Russian oil and gas supply is uncertain, the EU is now faced…
the imagery trusted to keep Europe safe, Productive & Moving Forward the imagery trusted to keep Europe safe, Productive & Moving Forward In the…
Sun glint occurs when sunlight reflects off water or another reflective surface at the satellite sensor, creating a bright glare in the image. That…
Intelligent Collection Planning (ICP) The key to more efficient collection of large areas and difficult weather conditions Superior TASKING for your project Scalable Tasking…
THE 123 OF AEC: Renewing the Architecture, Engineering and Construction Industry with Satellite Imagery | A reoccurring sustainable issue faced by the Architecture, Engineering…