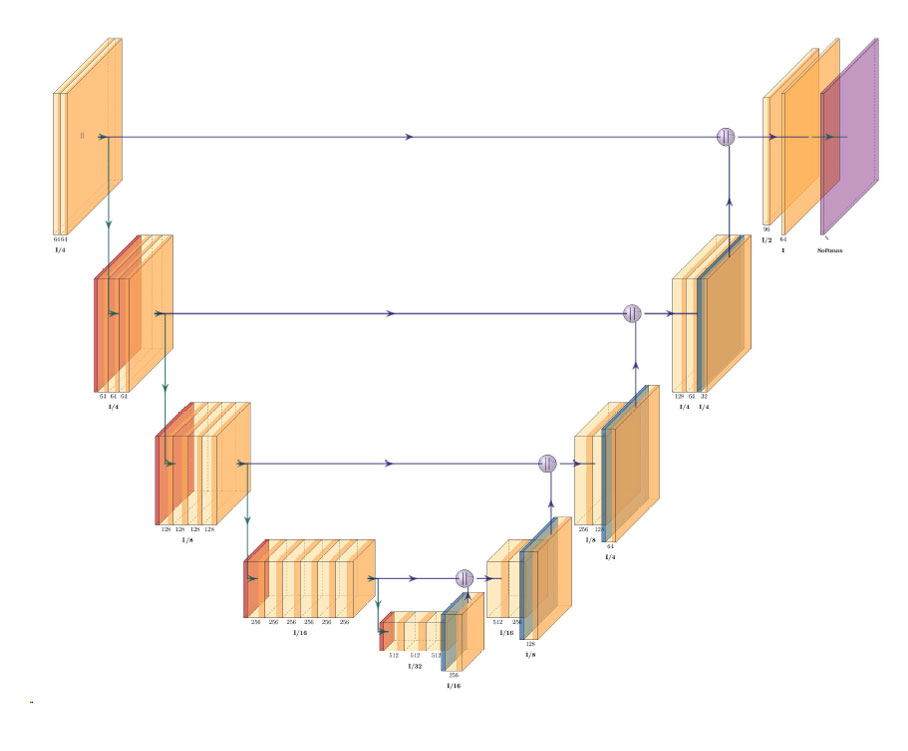
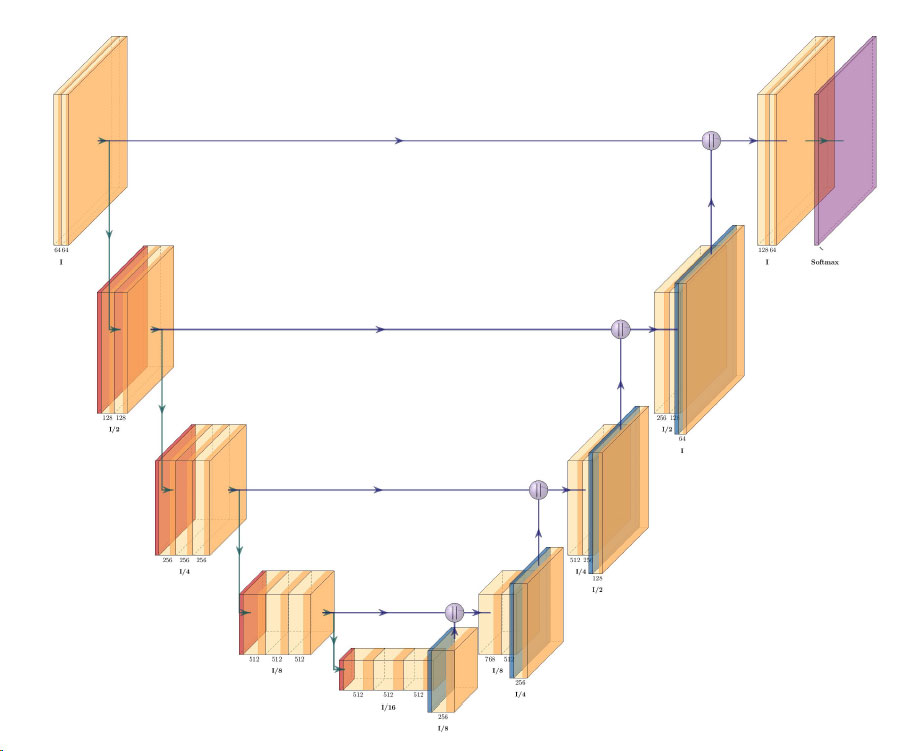
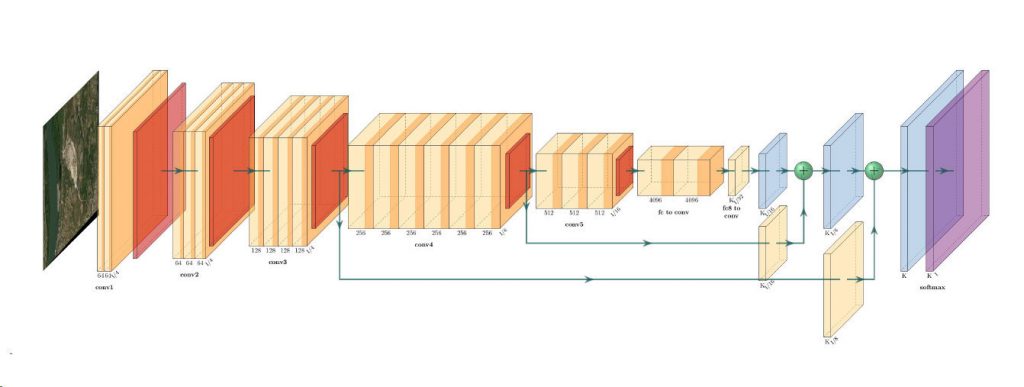
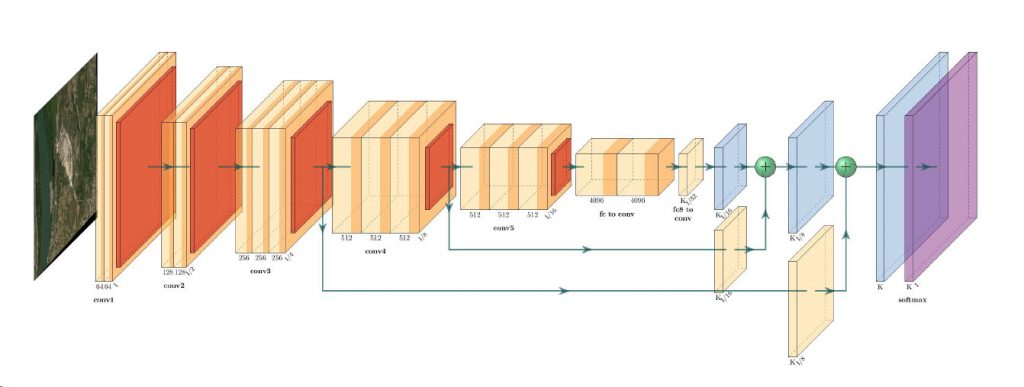
In cities around the world highways are being torn down so waterfronts can be reclaimed for public use. For many decades, cities have focused…
Terms & Conditions PRODUCT TERMS AND CONDITIONS Version F1-28-19 PLEASE READ THESE PRODUCT TERMS AND CONDITIONS CAREFULLY BEFORE USING ANY EUROPEAN SPACE IMAGING /…
The Hartibaciu Tableland encompasses about 2,500 square kilometers in central Romania and is home to many rare species of birds, flora, and fauna. It…
European Space Imaging have partnered with EOVision to produce a book entirely comprised of satellite imagery showcasing the diversity of Europe as seen from…
A satellite image captured by WorldView-2 on 27 February 2019 confirms that the religious school run by Jaish-e-Mohammed in northeastern Pakistan appears to still…
A mudslide has caused a motorway bridge near Savona, Italy, to collapse leaving a 30-metre gap in the road. Satellite imagery supplied by European…
Privacy Policy We’re committed to keeping you safe European Space Imaging is serious about protecting your data, and have created this privacy policy to…
Munich, Germany – European Space Imaging (EUSI), the leading provider of Very High Resolution (VHR) satellite imagery in Europe, is thrilled to announce a…